gameofdimension.github.io
隐马可夫模型与中文分词
前段时间为了建模模板问题,研究了一下 hmm 模型,虽然最终并没有用 hmm 来解决模板问题,但是好歹 hmm 给我们提供了重要的思路。在这里把之前了解的关于 hmm 的知识总结记录一下。
hmm 假定观察到的事实是由不可观察的隐藏变量决定的,同时此刻的隐藏变量只取决于上一时刻的隐藏变量状态,而与再之前的隐藏变量状态无关。同时这种依赖关系也与时间无关,也就是说时刻1时隐藏变量对时刻0时隐藏变量状态的依赖关系跟时刻10时隐藏变量对时刻9时隐藏变量的依赖关系完全一样。假定时刻 t 时的隐藏状态为 \( s_t \),此刻的可观察变量为 \( o_t \)。用数学公式表达以上关系则为:
\( p(o_t|o_{t-1},o_{t-2}..,s_{t-1},s_{t-2}..) = p(o_t|s_{t-1}) \)
\( p(s_t|s_{t-1},s_{t-2}..) = p(s_t|s_{t-1}) \)
\( p(S_t|S_{t-1})=constant \)
要说明的上面第三点并不是说对于某个具体相邻时刻隐藏状态赋值有这种关系,而是说只要相邻的两个时刻隐藏状态赋值一样,这种概率关系与时间无关。而相邻的两个时刻隐藏状态赋值是有许多种可能的。
于是从定义上讲,一个 hmm 由以下5个元素构成:
- StatusSet:隐藏状态集合
- ObservedSet:观察值集合
- TransProbMatrix:隐藏状态之间的转移概率矩阵
- EmitProbMatrix:隐藏状态决定观察值的发射概率矩阵
- InitStatus:初始状态概率分布
hmm 模型中通常有三类问题:
- 已知模型参数和观察序列 \( (o_1,o_2,..,o_T) \) ,求观测序列在给定模型下出现的概率。
- 已知模型和观察序列,求概率最大隐藏状态序列。
- 已知观察序列,估计模型参数。也就是求得模型参数,使得在此模型下,观察序列出现的概率最大。
第一类问题只是简单的计算问题,只是其中计算方法需要些技巧,一般的方法是动态规划,分前向与后向两种思路。
第三类问题因为输入信息量少,但是输出信息量却很大,其效果也要打问号。一般的求解方法是 EM 算法。
第二类问题应用广泛,比如著名的中文分词问题就可以用其建模。接下来就详细说明一下。
假定有一个中文句子:“隐藏状态之间的转移概率矩阵”。这里的每个汉字就对应一个观察值,而观察值背后的隐藏状态则如下定义:
B:词开始 M:词中部 E:词结尾 S:单字成词
比如“隐”字对应的隐藏状态就是 B , “藏”字对应对应的隐藏状态就是 E , “的” 字对应的隐藏状态就是 S 。对于一句话我们只要确定了每个字对应的隐藏状态,也就确定了这句话的分词方案。
对比上面的模型5要素,我们已经有了 StatusSet, 而另外四个部分都可以通过统计语料库获得。
对于我们要解决的问题,当然有一个 naive 的算法,就是枚举所有可能的隐藏状态序列,计算其概率,选择对应概率最大的那个序列赋值。这个算法虽然直观,但是确是低效的,其时间效率是指数级别的。
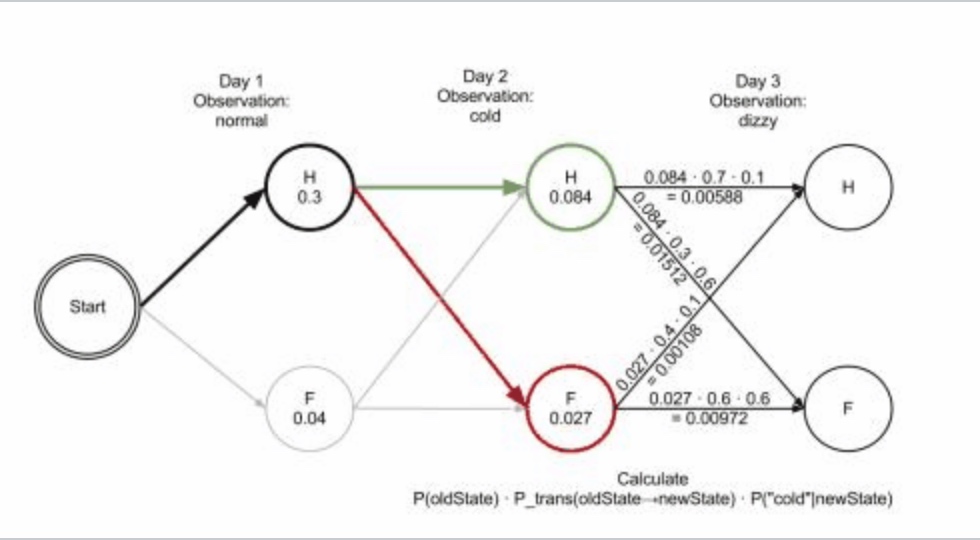
通常解决这个问题的算法是维特比算法,这个算法其实也就是动态规划方法的具体应用。如下面这张图,就是要求从起点 start 开始,经过中间每一层到达最后一层的一个最大路径。要注意的是这个图是有向的,而且只在相邻层之间有边连接。将问题做了这样的抽象之后,要得出详细的递推关系也就不难了,具体可以参照维基百科。
参考:
统计学习方法,李航 中文分词之HMM模型详解 维基百科