gameofdimension.github.io
我所理解的 AlphaGo Zero 算法
- 神经网络只有一张,输入是棋局最近16步,双方各自最近8步的历史棋局状态。
- 神经网络用来拟合两个函数,因而有两个输出。其中一个输出是一个离散分布,给出19*19个位置和 pass 共362个动作选项的概率分布。另一个输出是-1和1之间的实数值,表示对当前局面的一个打分,-1表示输,1表示赢。
- 算法主要分为两个部分,一部分是神经网络的训练和评估;另一部分则是基于 MCTS 的自我走子。
- 对于围棋这种完全信息的零和博弈,理论上是可以用搜索算法完美解决的。当然前提是我们有足够的计算资源,而这一点是没法做到的,毕竟搜索的状态空间比全宇宙的原子数还要多。
- 神经网络的作用是在不搜索到状态树根据规则胜负已分的局面的前提下也能给出对当前局面的一个比较合理的评估。
-
整个算法表示在下图中:
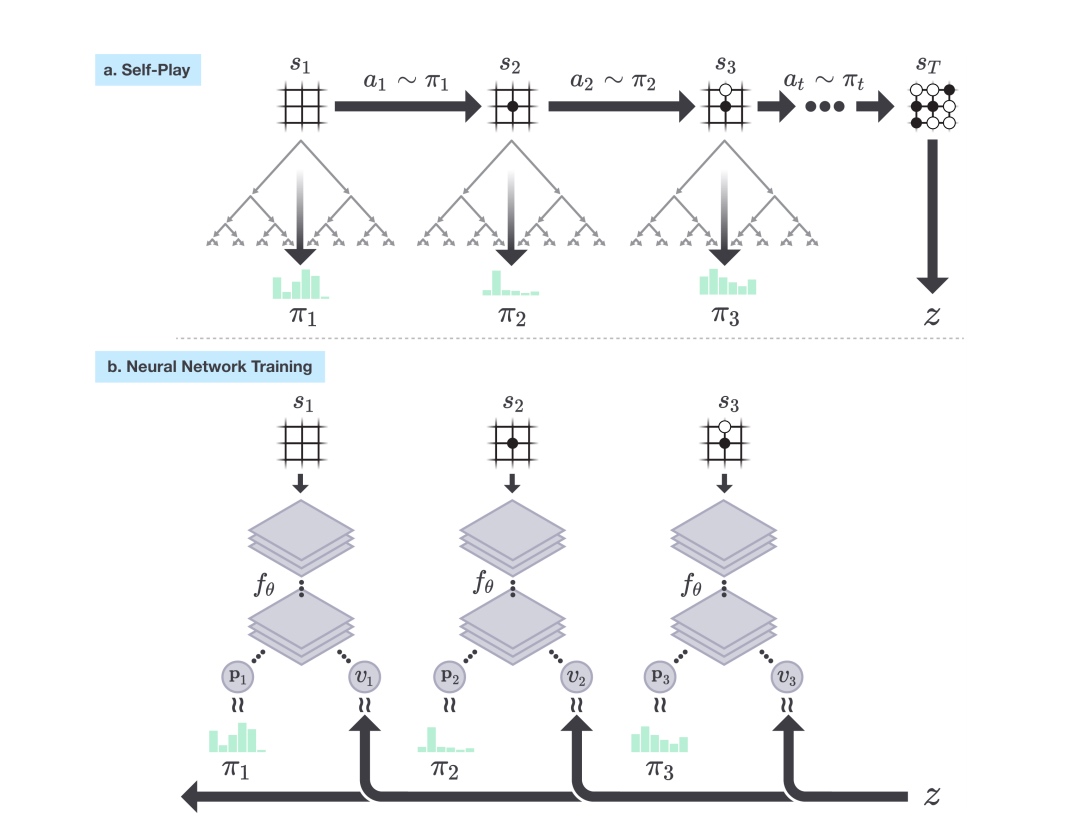
- 每一个自我走子(self-play)阶段包含25,000局自我对战的棋局,每一局都要战到最后状态。
- 每一步的具体走子选择经由 1,600 次模拟(搜索)决定,每一次模拟都是在当前的搜索树中进行。
- 每一次走子搜索的结果是一个概率分布,给出的是当前状态下搜索过程认为的下子选择,这个走子选择被认为优于神经网络走子选择,因此是神经网络的拟合对象,这个概率分布以及当前的棋局状态会保存下来作为后续神经网络的训练数据。
- 每一局自我走子走到最后,根据围棋规则可以分出胜负,从而被打分-1或者1,也就是上图中的 z 值。这个值会和上面的搜索过程走子概率分布一样附加到每一步的棋局状态上,作为神经网络要拟合的另一个目标。
- 神经网络训练会从积累的训练数据集中抽取数据进行训练,训练完成之后会使用该网络和之前的网络进行对抗,如果新网络胜率超过55%,则将更新当前网络为新网络。并循环执行以上各步骤。
-
搜索过程如下:
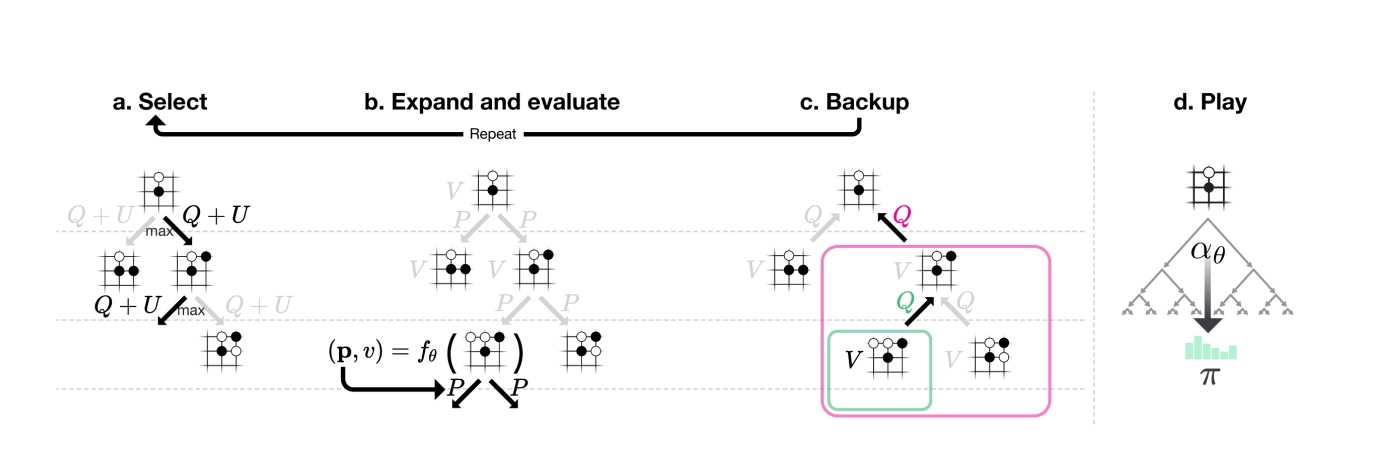
- 搜索树中节点代表棋局状态,边代表走子选择,每一条边上会有几个数值,这几个数值是搜索过程中走子选择的依据。每一次具体的搜索过程也会改变搜索路径上每一条边的这些值。
- 每当搜索树扩展出新节点时,新节点下的走子选择以及新节点的价值会由当前的神经网络给出。得到的新节点的价值会导致路径上各条边的价值都得到更新。每次扩展到新节点也表示本次搜索过程结束。
参考: